Test cases limited to particular app for django
At TaxSpanner as we were entering the "filing season" we wanted an continues integration system in place which could tests independent apps and stage them for further testing. We setup jenkins, created pipeline for different apps but as models grew and migrations were getting added, the whole pipeline started crawling.
There are different moving parts in whole application, say app1, app2, app3 and so on. While many of applications do interact with each other using API's but somehow application level testing using manage.py doesn't exactly limit things to just that particular app. What I mean is, say I am working on app2 running its test using
./apps/manage.py test app2
will still load all installed_apps and try to get your "test DB ready with all models, indexes and migrations". With the complicated models this preparing process itself was taking hours(2 hrs+). I am not sure about what would be standard approach for such a setup, should we "include" settings from each app individually? Anyway, so because of that behavior of django's test suite we struggled and even started avoiding writing/running tests.
Somedays back, as we started work on revamping an app around django-rest-framework and I was again stuck at this issue. While looking around I was just experimenting with settings and added this "hack" at the end of settings.py
import sys
if 'test' in sys.argv or 'test_coverage' in sys.argv:
INSTALLED_APPS = ('app2', 'rest_framework', 'usermanagement',
'django.contrib.sites', 'registration',
'django.contrib.sitemaps',
'django.contrib.webdesign',)
and voila, my tests were back on track, under a minute(~10 seconds) with no unrelated apps. There were further suggestions to make things more faster by team :
DATABASES['default']['ENGINE'] = 'django.db.backends.sqlite3'
and further to avoid migrations,
class DisableMigrations(object):
def __contains__(self, item):
return True
def __getitem__(self, item):
return "notmigrations"
MIGRATION_MODULES = DisableMigrations()
Pankhudi work in January
I met one of my school friend earlier in the start of this month and he was mentioning about how he and his wife were trying to teach some kids from neighborhood but society people interfered saying rogue kids are entering society premises on excuse of class and causing trouble. They "suggested" the couple to rent a room somewhere outside and take classes there. Of course, this is outrageous to expect someone to take such an extra measure to actually do something good and in the end, they just left.
It was really sad to hear their part of story but I am really fortunate to have totally different set of people around me. I recently started working with TaxSpanner Team. Before joining them in Delhi, I was concerned about how I would be able to continue with work done till now with Pankhudi/पँखुडी. I was wondering if I could come down to Pune and continue working from here once I am all set with the team and working methodology. Ankur, Gora, Vivek and others readily agreed and I spent last two weeks of January here.
In library there was issue with earthing and computers had been down from quite some time. Thanks to Srikant, Padma and Pratiksha's(maybe I missed others name) effort we had proper working switch boards in library which were needed BIG time. Computer, Raspberry Pi(we have offline Wikipedia, Khan-academy videos, scratch and other resources on it, though use case is still very limited), Laptop, all were working just fine. Also, people "hosted" me so readily, provided all resources(office to work from, vehicles to commute, even pick and drop facility, lunches/dinners/snacks), that one feels right at home and carry on with the work/anything without any adaptation, Sooper it is(घन्यवाद बोला तो लोग मारेंगे). Hope to see you all again soon :)
Here are logs of activity going on in library while I was there
| Date | Reached | Left | Children | activity | Notes |
|---|---|---|---|---|---|
| Rukhsar+Zainab+Afreen | reading chapter, Eyes are not here. | Was away for | |||
| Task: Mark verb+tenses of sentences | almost 45 minutes(snacks) | ||||
| Sangita | We covered some DB related basics, | ||||
| firing some queries, | |||||
| chalked out "Schedule" for this week. | |||||
| Anas | He was making excel sheet for | ||||
| Attendance of volunteers+students | |||||
| Aashique | doing something with Excel+ppt+alice | ||||
| Neha | Pen-Drive Cleanup+Caution about using | ||||
| Pendrive on systen in case of viruses | |||||
| Sangita | Given her installation+manual, asked | ||||
| her to follow instruction in pdf to | |||||
| install sqlite3(lighter verions SQL) | |||||
| Status: Finished installation, | |||||
| create, insert, query | |||||
| Rukhsar | Status: Finished tenses kehte | ||||
| Umar | Trying random things on computer | Break: | |||
| Rukhsar | Chapter : Gift of Magi tenses/words | ||||
| HW: Rewrite first two para in simple | |||||
| Ashique | Studying Urdu kehte | to | |||
| Status: Covered 2 first para, meaning | Was in boat club got some | ||||
| Sangita | Revision+Foreign Key | office work. | |||
| Status: We barely got to point of | Somehow network connection | ||||
| creating tables with Foreign key | is very bad in library | ||||
| Junaid | Studying Cpp from Padma | ||||
| Brief mention of HW networking coruse | |||||
| Rukhsar | Didn't get time to do work so doing | ||||
| it right here in library | |||||
| Reading random eng chapter | |||||
| Sangita | they have oracle in college | ||||
| Interface is different, syntax same | |||||
| Left in between, poonam needed system | |||||
| Sangita | Installing Oracle+sql she got from | ||||
| college+Foreign Key+DataBackup/Resore | |||||
| Rukhsar | |||||
| Neha | Wanted to know how to use Pi+Wiki | ||||
| Rukshar | Practice question+answers | ||||
| + Co | |||||
| Sangita | She is practicing her school HW relat | ||||
| -ed to DB, constraints. | |||||
| Anas | Doing Math's limt exercise | ||||
| Junaid | Doing Math's limt exercise | ||||
| Neha | Some work she is doing… Subject | ||||
| Rukhsar | Following up hindi assignment | ||||
| Junaid | |||||
| Anas | Did small review of concept of limits | ||||
| Priti | Studying with Aditi. | ||||
| Sangita | Joins, group by, queries. | ||||
| Ashqui | Giving hand with Rukhsar's student | ||||
| Sangita | She was here already, class exercise | ||||
| query, joins, select statement | |||||
| Anas | doing some math factoring | ||||
| Ashique | Doing something with english grammar | ||||
| Junaid | |||||
| Ashfaq | Doing Grammar work |
| DATE | TOPIC | TIME |
|---|---|---|
| INSTALLATION | ||
| CREATING TABLE | ||
| QUERY AND INTERFACE | ||
| LOAD Data/Insert/Drop/delete | ||
| Relationships(Foriegn Keys) | ||
| Query on related tables | ||
| Many to Many/ | ||
| One to Many/ | ||
| Many to One fileds | ||
| Joins/Relationships/ | ||
| Set/Unique/intersections | ||
| Indexing+Queries | ||
| Revisions |
Document Images Retrieval using Word Shape Coding
tl;dr here is the code
Problem statement:
Given a scanned image, search for a sub-patch containing a particular word without doing OCR.
Like for this text image 
we have to find location of patch with the word - streaming
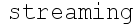
Approach
Initially I was thinking of extracting features(using SURF) from the image and the patch and comparing them. But with sample programs, I was getting features matched throughout the image. I tried to create individual image patches for each word, find features and then do matching but still didn't get any results.
I came across some works related to searching terms in document images. They followed the approach of segmenting the image into word patches, extracting features based on word shapes and then carried out comparison. I looked for a library implementation but didn't come across anything so thought of giving it a try.
At the moment I am using 6 features. Like for a word image, for each horizontal pixel, extract position of extreme top foreground pixel. For the sequence, use DTW algorithm to find the best match across the segmented patches. Other features I am using are height of foreground pixel, bottom extreme and same way left and right extreme for each height pixel. So for above mentioned image patch of word streaming here are plots of different features:
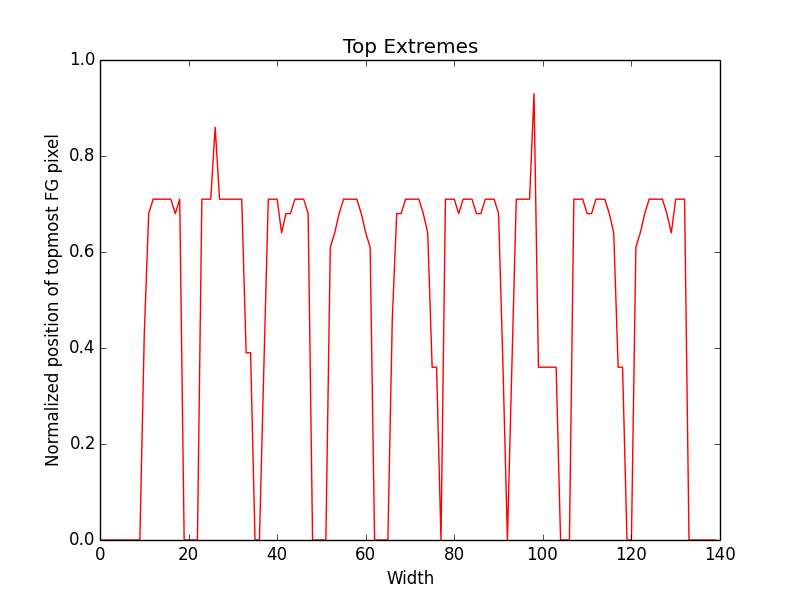
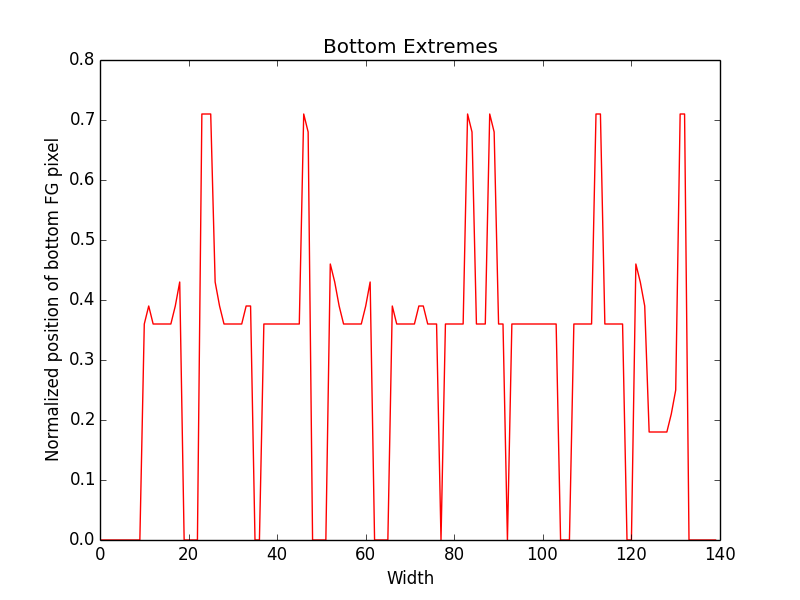
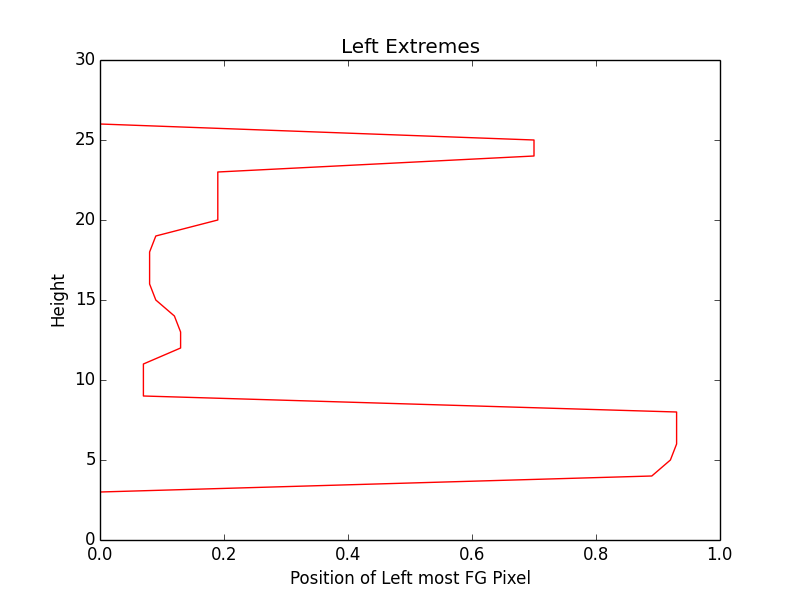
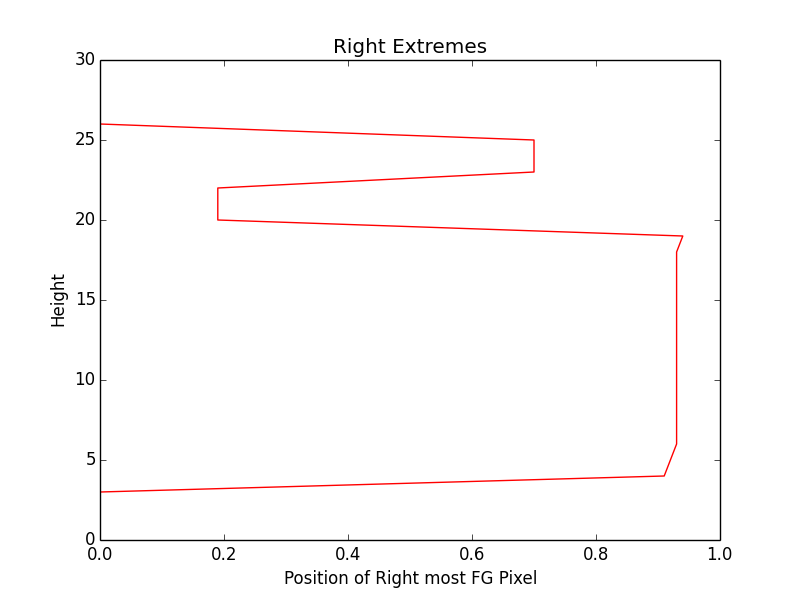
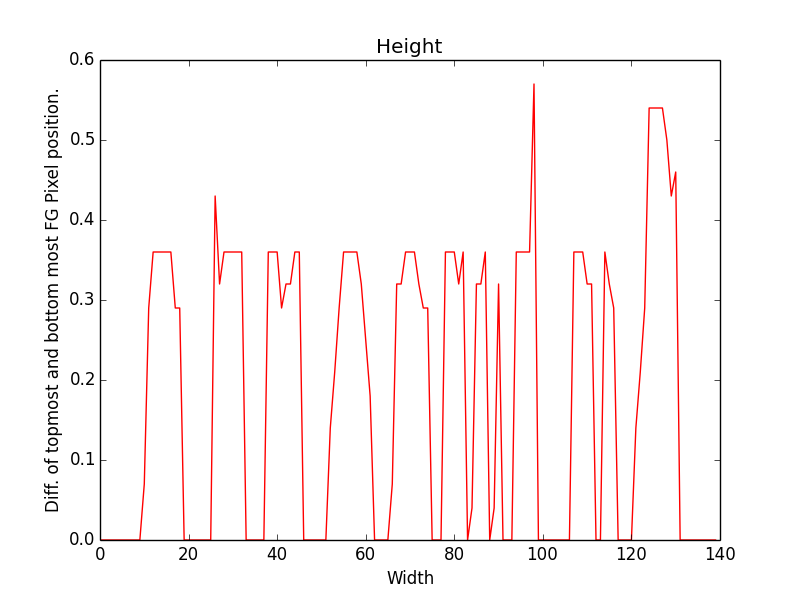
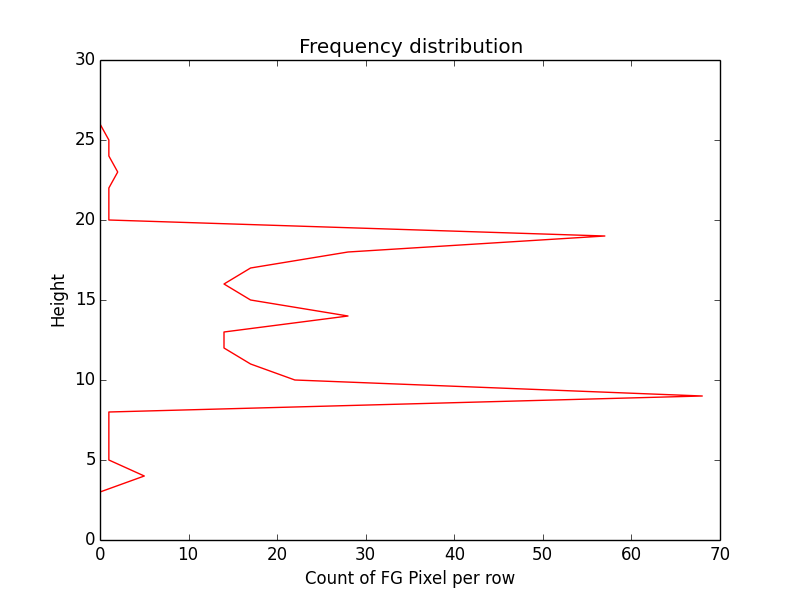
Performance
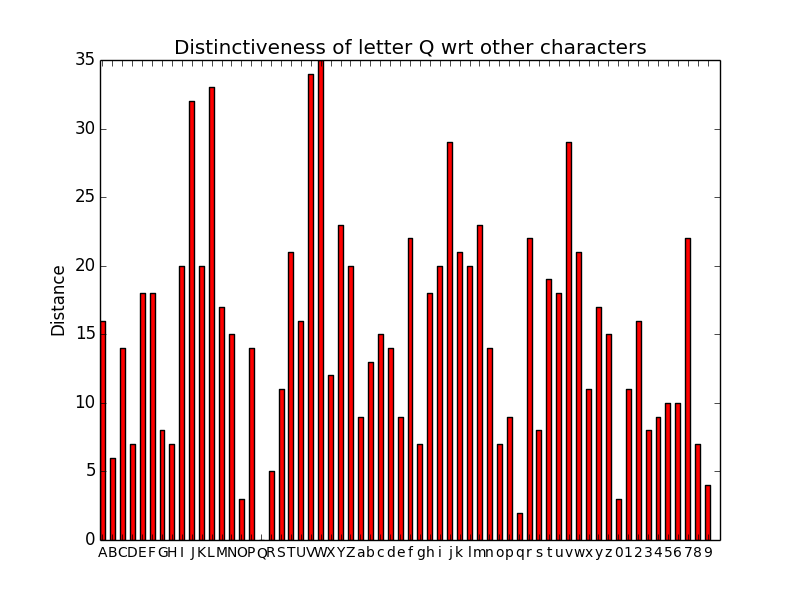
Till now I have got some positive results using above features. I
compiled list of characters using one particular font and tested the
measure of distinctiveness of each character wrt other characters.

And here is the graph of distance measure of alphabet Q with rest
of characters
I tested it with words using a test image of words taken from sample text image and tried some fonts to check the robustness:

When I tried to locate words from this image in the sample text
image
I got 17 word blocks identified(should improve this too) and out of them 15 were correctly identified/matched to right patch in text image.
TODO
- Understand SURF and Homography and confirm if it works in this particular case or not.
- Look for more meaningful features(maybe using DFT) which can be help with improving performance.
- Use Sakoe-Chiba band for DTW and partial matching as mentioned in the paper.
- Exhaustive testing for getting better stats of performance.
Multilingual Document Clustering
After my last post I was following the TODO block to see if I can get a simple multilingual document clustering (MDC) working. First step was to see if we simply translate Hindi documents into English, word by word and then run Clustering algorithm over it, do I get same results as that of clustering documents in their original language.
I used translate python package to convert all documents to English using following code
from translate import Translator
from os import path
import pickle
import string
# adding Hindi punctuation to regular English punctuation
unicode_punctuation = string.punctuation+u"\u0964\u0965"
translate_table = dict((ord(char), u" ") for char in unicode_punctuation)
stop_words = [word.decode("utf-8") for word in stopwords.words("hindi")]
translator = Translator(to_lang="en", from_lang="hi")
if path.isdir("hi_dict"):
hi_dict = pickle.load(open("hi_dict"))
else:
hi_dict = {}
for link in links:
content = link["content"].translate(translate_table)
content = " ".join(content.split())
tr_words = []
for word in content.split():
if word in stop_words:
continue
if word in hi_dict:
tr_words.append(hi_dict[word])
elif word.isdigit() or not word.isalpha():
tr_words.append(word)
elif word.istitle() and word.lower() not in hi_dict:
print word
tr_words.append(word)
else:
eng_word = translator.translate(word.encode("utf-8"))
hi_dict[word] = eng_word
print word, eng_word
tr_words.append(eng_word)
link["content"] = " ".join(tr_words)
pickle.dump(hi_dict, open("hi_dict", "w"))
Here links is simple data structure which stores the urls and text
content of those web pages. At this stage, I perform clustering over
this translated text. I got were in sync with my previous
.
With this hypothesis working I mixed up data(in English) which I used in my first post and this translated data. After shuffling data and playing around with parameters I used following code to run clustering algo.
import numpy as np
from sklearn.feature_extraction.text import TfidfVectorizer
from random import shuffle
from sklearn.metrics.pairwise import linear_kernel
shuffle(links)
blobs = [link["content"] for link in links]
vectorizer = TfidfVectorizer(stop_words = "english", ngram_range = (2, 3), max_features = 100000)
corpus_mat = vectorizer.fit_transform(blobs)
cosine_similarities = np.zeros((len(blobs), len(blobs)))
for i in range(len(blobs)):
cosine_similarities[i] = linear_kernel(corpus_mat[i:i+1], corpus_mat).flatten()
cosine_similarities[i, i] = 0
# Majorclust algorithm
t = False
indices = np.arange(len(links))
while not t:
t = True
for index in np.arange(len(links)):
# aggregating edge weights
new_index = np.argmax(np.bincount(indices,
weights=cosine_similarities[index]))
if indices[new_index] != indices[index]:
indices[index] = indices[new_index]
t = False
# Organizing the end results
clusters = {}
for item, index in enumerate(indices):
if "title" in links[item]:
title = links[item]["title"].encode("utf-8")
clusters.setdefault(index, []).append(title)
else:
clusters.setdefault(index, []).append(links[item]["url"].encode("utf-8"))
op_file = open("op-mixed", "wb")
for item in clusters:
op_file.write("\n"+80*"="+"\n")
op_file.write("\n".join(clusters[item]))
op_file.close()
For this code links contains all translated articles and articles
written in english, and this is the complete .
Inferences
There are false positives in the results(like kafila posts being part of cluster related to technology) but having results like
,
http://kafila.org/2013/12/08/aap-halts-bjp-advance-in-delhi/
!
http://kafila.org/2013/11/15/first-terrorist-of-independent-india/
and
http://arstechnica.com/tech-policy/2013/12/nsa-collects-nearly-5-billion-cellphone-location-records-per-day/
,
!! !!
http://arstechnica.com/tech-policy/2013/12/microsoft-google-apple-call-for-end-to-nsas-bulk-data-collection/
Google Play:
http://techcrunch.com/2013/12/11/google-android-device-manager-play-store/?utm_campaign=fb&%3Fncid=fb
give some hope that with some more work and refined data and better translations we might have something more robust.
TODO
- I will work on better way to test the results, which can give better idea about false positives and performance.
- To try other algorithms with same dataset and compare results.
- Extend the idea to include other languages too.
- If possible create a small proof-of-concept app around it.
- Release a format of dataset which can be used by others to get started.
Document clustering in Hindi
As it turns out, since most of clustering algorithms don't depend on grammar or language specific constructs so if we remove stopwords and do a proper stemming, we should be able to use same Major Clust algorithm for hindi blogs too. I looked around for some active hindi blogs and via Indian Bloggers got the link of कस्बा/qasba blog maintained by रवीश कुमार जी(Ravish Kumar). But topics covered in that particular blog were mostly related to politics, so I needed some more diverse dataset to test effectiveness of clustering algorithm. I came across feed of Jagran Junction and was able to get feeds related to sports and technology in hindi.
After some cleanups(removing duplicate articles, punctuation, minimum
length of article) and using almost same code as we used for
clustering English articles I got decent/acceptable for hindi
documents too.
One thing which I had to take care while tokenizing hindi text using default TfidfVectorizer was, default re module for python 2.7 was failing in my case for unicode characters(1, 2) and seems it is fixed in regex. So I used this custom code to get it working.
def regex_tokenizer(doc):
"""Return a function that split a string in sequence of tokens"""
import regex
token_pattern=r"(?u)\b\w\w+\b"
token_pattern = regex.compile(token_pattern)
return token_pattern.findall(doc)
stop_words = [word.decode("utf-8") for word in stopwords.words("hindi")]
vectorizer = TfidfVectorizer(stop_words = stop_words,
tokenizer = regex_tokenizer)
vectorizer.fit_transform(blobs)
features = vectorizer.get_feature_names()
Some additional points
- Always shuffle your data.
- I got stopwords for hindi by combining list posted on sarai mailing list, Indian language technology IITB group and IR Multilingual Resources at UniNE
TODO
- Clean up more, use stemming etc and check the results.
- Translate the text to English(word by word) and confirm if we get same results for clustering new text.
- If previous experiment works out, move on to test multiple language document clustering.
- Analyze important words being returned for a document using tf-idf and lsa.
References
- http://www.stevenloria.com/finding-important-words-in-a-document-using-tf-idf/
- http://www.mblondel.org/journal/2010/06/13/lsa-and-plsa-in-python/
- http://members.unine.ch/jacques.savoy/clef/index.html
- http://hlt.di.fct.unl.pt/luis/hindi_stemmer/index.html
- http://stackoverflow.com/questions/4007558/is-there-is-any-stemmer-available-for-indian-language
- http://web2py.iiit.ac.in/publications/default/download/inproceedings.pdf.a238b927919ec29b.4d44435f69726663323031315f70617065722e706466.pdf
- http://www.isical.ac.in/~clia/
- http://aimotion.blogspot.in/2011/12/machine-learning-with-python-meeting-tf.html
- http://irsi.res.in/
- https://github.com/translate/translate
Tesseract:Correcting page orientation
Recently for work I had to deal with doing OCR over inverted pages,
something like this 
I came across some threads(1, 2, 3)on tesseract google group and StackOverflow which were close to problem I was dealing with. I tried example mentioned on tesseract API page, looked at OSDetect code(4) and though it has already couple of implementations like updatebestorientation somehow it was not working for me. Maybe I was doing something wrong but eventually I ended up with following code which works for me, it rotates the page despite the top line.
#include <tesseract/baseapi.h>
#include <tesseract/osdetect.h>
#include <leptonica/allheaders.h>
int main(int argc, char **argv)
{
OSResults os_results;
tesseract::TessBaseAPI *api = new tesseract::TessBaseAPI();
if (api->Init(NULL, "eng")) {
fprintf(stderr, "Could not initialize tesseract.\n");
exit(1);
}
Pix *image = pixRead(filename);
api->SetImage(image);
// To detect correct OS and flip images
api->DetectOS(&os_results);
OrientationDetector os_detector = OrientationDetector(&os_results);
int correct_orientation = os_detector.get_orientation();
// Had to add this condition because get_orientation result and
// pixRotateOrth were not in sync.
if (correct_orientation == 1) {
image = pixRotate90(image, -1);
}
else if (correct_orientation == 3) {
image = pixRotate90(image, 1);
}
else if (correct_orientation == 2) {
pixRotate180(image, image);
}
api->SetImage(image);
char* ocrResult = api->GetUTF8Text();
fprintf(stdout, "Recognized Text: %s\n", ocrResult);
api->End();
pixDestroy(&image);
delete [] ocrResult;
return 0;
}
Clustering text using MajorClust
TL;DR here is public gist
Introduction
I had a conversation with 9 about clustering links based on content and he pointed me to a StackOverflow(SO) conversation about getting started with it. It is very simple concept, but I had to stare at the pseudo code of paper, StackOverflow, results of different sample-sets, for quite some time to understand what is actually happening.
n = 0, t = false
v V do n = n + 1, c(v) = n end
while t = false do
t = true
v V do
c = i if (u, v) is max.
if c(v) != c then c(v) = c , t = false
end
end
For example dataset mentioned in StackOverflow
texts = [
"foo blub baz",
"foo bar baz",
"asdf bsdf csdf",
"foo bab blub",
"csdf hddf kjtz",
"123 456 890",
"321 890 456 foo",
"123 890 uiop",
]
If we try to plot initial graph based on cosine distance among all
the nodes(each element of texts list) we get something like this:
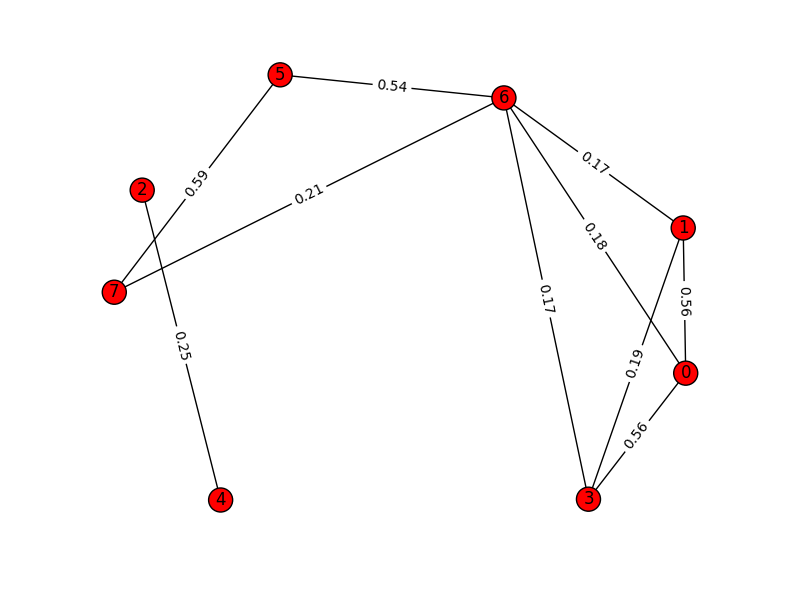 And once we cluster the graph using MajorClust algorithm, the graph
get restructured to:
And once we cluster the graph using MajorClust algorithm, the graph
get restructured to: 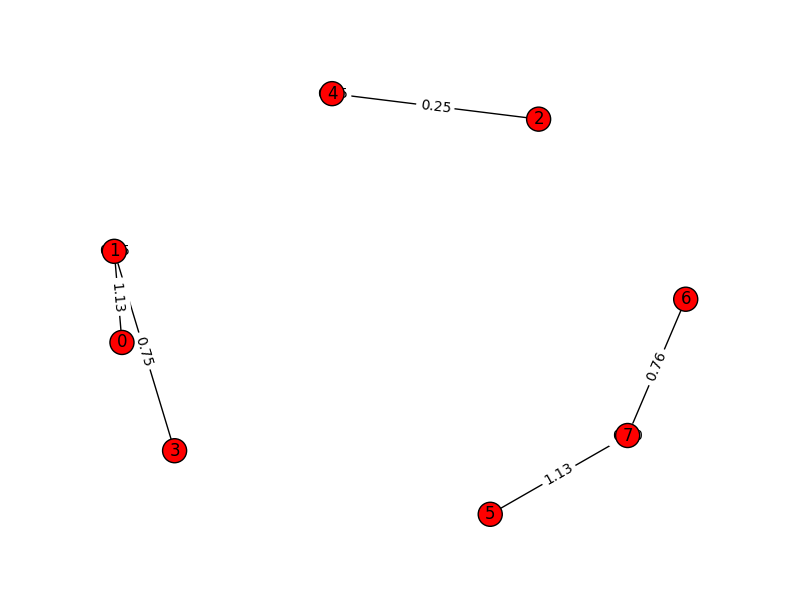
Notice how edges get aggregated and new weights are assigned to edges based on clusters and not-so-important edges are dropped altogether.
Code
The code on StackOverflow thread is complete without any external dependencies. I used TfidfVectorizer from sklearn to create vector space model from the documents(different and bigger dataset).
# corpus is list of all the documents
vectorizer = TfidfVectorizer(stop_words = "english",
ngram_range = (2, 3),
max_features = 100000)
corpus_mat = vectorizer.fit_transform(corpus)
num_of_samples, num_of_features = corpus_mat.shape
Then, I calculate cosine distance of each vector(document) from other vectors.
magnitudes = np.zeros((num_of_samples))
# this loop can be removed?
for doc_id in range(num_of_samples):
magnitudes[doc_id] = np.sqrt(corpus_mat[doc_id].dot(corpus_mat[doc_id].T).sum())
cosine_distances = np.zeros((num_of_samples, num_of_samples))
# this loop can be improved
for doc_id, other_id in combinations(range(num_of_samples), 2):
distance = (corpus_mat[doc_id].dot(corpus_mat[other_id].T).sum())/(magnitudes[doc_id]*magnitudes[other_id])
cosine_distances[doc_id, other_id] = cosine_distances[other_id, doc_id] = distance
This cosinedistances matrix is adjacency matrix representation of the graph, where each node is one document and edge weight(cosine distance) being the measure of similarity among two documents. Now MajorClust algorithm is clustering based on aggregating/accumulating edge weights and assigning each node to cluster which has maximum accumulated edge weight.
t = False
indices = np.arange(num_of_samples)
while not t:
t = True
for index in np.arange(num_of_samples):
# aggregating edge weights
new_index = np.argmax(np.bincount(indices,
weights=cosine_distances[index]))
if indices[new_index] != indices[index]:
indices[index] = indices[new_index]
t = False
clusters = {}
for item, index in enumerate(indices):
clusters.setdefault(index, []).append(links[-50+item]["url"])
This bit might be confusing, I was stuck here for quite some time, maybe images of graph above might help.
Experimentation and results
For testing the performance of algorithm I took facebook pages of
three websites techcrunch, arstechnica, kafila(two of them cover
articles related to tech, science and third one is about Indian
politics and media). Using fbconsole I got last 50 links(only
english stories) which have been shared, scraped content of those
links and ran MajorClust over this data. I had to play around with
Tf-Idf parameters like using stop words, ngrams(2 and 3) to get
decent . Once I had it, I ran it on single group(kafila) to
create more
out of posted stories.
Next..
- Try to profile FB friend circle based on links they are sharing.
- Other clustering algorithms, k-means etc.
- Running this algorithm with different situations(like streaming data).
भैया अगली बार से English पढते हैं/Lets study English from next class.
We had four days during diwaali break and some of other people from Pankhudi group were also mulling over introducing programming to kids. I was working with UC for this possibility of doing home automation so we thought it would be nice to start with Arduino, Pi etc to give kids a real feel about how things can be programmed.
We had one arduino, some LED's and one relay switch. I was thinking of showing how easily we can control manual switches using programming. We passed around arduino board, pointed out some pins etc for a small intro and then wired up things. I was using nanpy and ipython console to pass commands to Arduino. One line of code and we had leds, bulbs blinking.
Arduino.digitalWrite(13, Arduino.HIGH)
Arduino.digitalWrite(13, Arduino.LOW)
This initial group was bigger one, so I was not able to cover details etc, but mostly ended up "showing off" for random requests of what else can be done. But once kids got settled that there were not too many things, some stayed back while others drifted. Then we had a sort of extensive conversation about use cases, possibilities, why, how etc.
As other volunteers joined, there were parallel classes going on, and I was just covering same demo with some more details to different set of kids. Then I had couple of girls who started off with, यह क्या है भैया? After the answer their next question was, आप क्या काम करते हो? And here I slipped(mistake), I had a program open in editor, so I showed them those 5-10 lines and said, this is what I do, they were like ehh? and I replied, yeah we write programs like this and get paid. Now those 5-10 lines were not that complicated, but it certainly gave a wrong impression, and they were totally convinced to learn this skill.
Now with a limited focused audience, we got more time and over next few classes we covered some details of programming constructs. Good thing of using IPython is, it gives live interaction with system. First thing we covered was flipping the state of LED and hence introducing "if-else" construct or we called it something in lines of "या तो ये, नहीं तो ये"
if Arduino.digitalRead(13):
Arduino.digitalWrite(13,Arduino.HIGH)
else:
Arduino.digitalWrite(13,Arduino.LOW)
We covered ideas like what is this if-else condition, indentation part here and in later parts. Next thing we moved onto was, making LED blink.
from nanpy import Arduino
Arduino.digitalWrite(13,Arduino.HIGH)
Arduino.digitalWrite(13,Arduino.LOW)
Now for this, we had to write a small python script and run it, and also concept of how computer runs this script line by line(instructions). But with this program, LED blinked very quickly so we introduced sleep function and how to call it with different parameters. Also a brief mention of import business we are doing.
from nanpy import Arduino
from time import sleep
Arduino.digitalWrite(13,Arduino.HIGH)
sleep(2)
Arduino.digitalWrite(13,Arduino.LOW)
From here we covered blinking a LED for a specific number of times(say 5 or 4). Firstly we landed up with idea that we can repeat lines 5(nth) times and we will get the task done. They wrote the program and tested if it was working. Now I introduced concept of looping(repeat something जब-तक), variable, counters.
from nanpy import Arduino
from time import sleep
counter = 0
while counter < 5:
Arduino.digitalWrite(13,Arduino.HIGH)
sleep(2)
Arduino.digitalWrite(13,Arduino.LOW)
sleep(2)
counter = counter + 1
Here it took some time to make them understand what all is going on, why are we doing what we are doing. Once comfortable(they took this more like a bitter pill) they experimented with variation of counters, increment, while loop conditions and also infinite loop conditions. We had different color LED's so we tried combination of switching them on, syncing them and they very promptly related it to Traffic lightning and Diwaali light decorations.
I had this small program/function which gives some sense of noise level of surroundings(using mircrophone of system), so we thought of using this and writing a program which changes color of LED as the noise level changes. We started off by doing some trial runs to get idea of what are the values we are getting for different noise levels, they came up with the logic of roughly at what values the color should switch, we did some trials and edits and eventually we had something like this:
from nanpy import Arduino
from time import sleep
from noise import getRMS
counter=1
while counter < 5:
noise = getRMS()
if noise == -1:
continue
print noise
if noise < 2000:
Arduino.digitalWrite(10,Arduino.HIGH)
Arduino.digitalWrite(8,Arduino.LOW)
Arduino.digitalWrite(12,Arduino.LOW)
elif noise < 4000:
Arduino.digitalWrite(12,Arduino.HIGH)
Arduino.digitalWrite(8,Arduino.LOW)
Arduino.digitalWrite(10,Arduino.LOW)
else :
Arduino.digitalWrite(8,Arduino.HIGH)
Arduino.digitalWrite(10,Arduino.LOW)
Arduino.digitalWrite(12,Arduino.LOW)
Pin 8 was green, 10 was blue and 12 was red(most noisy) and again they were quick to conclude that such LEDs can be installed in principal's room to give him idea of which class is going berserk. Next I was thinking of writing a small function which can return major component of color being shown to webcam and switching LED accordingly but didn't get that finished.
Now although this all looks good/decent approach, I was getting uncomfortable about missing something. Some kids are from elementary, while others are doing under-graduation but most of them are not from STEM background. So I am not sure on how to go about introducing ideas like lists, numbers, floating point numbers, complicated conditions. And also how to link all these with their needs/curriculum, I think I will have to go through their books to get better idea of what might appeal to them and make them do something which they themselves can use. I was not able to connect all these exercise with the starting idea of getting paid for doing these things. In last class while thinking these things, students were trying out scratch and they readily understood idea of "events" and control loops etc, but as the class ended without much of learning they said to me: "भैया अगली बार से English पढते हैं|"
Coding/Working with eyes closed...
Inspiration
First time when I saw Krishnakant work with this computer during presentation at freed.in 2009, I was really impressed. Then thanks to punchagan I also saw this talk on org-mode at google headquarters which had introduction by T.V Raman. Kk uses something known as screen reader which keeps on speaking aloud whatever he keeps typing.
I have this window next to my working table, and many a times, I end up gazing out of it for a long time. And changing focus from that sort of light to screen inside room takes some time. Many other things, keeps on popping up and one day I ended up wondering, how would be my experience of trying screen reader.
Try-Outs
Despite challenges, I am highly drawn by some of points:
- I won't be distracted by anything else visually, which I think is really strong and dominating sense.
- It might give a more focused work, thinking of just one thing and working on it.
- Rest to eyes.
Challenges can be:
- I am not sure about speed. I am getting comfortable with keyboard, but something constantly buzzing in ear might slow down things.
- Although eyes are closed, there is some constant voice in ears which might be distracting.
- How efficient would it be switching between windows and easy it would be to pickup from where I had left.
- How would I play songs in background while working?
Not sure how to go about it, but I would certainly give it a try and see how it goes.
Making travel more fun
Hello,
Introduction and Background
My name is Shantanu, I am currently working at Institute for Media Innovations, NTU, Singapore as a programmer. I have been here from past six months and many people have recommended me to use this opportunity to explore South-East Asia. I am a fan of travelling, I fully agree with Mark Twain, but still I am not as adventurous as one of my friend.
In the past, I have travelled to many places in India with friends, and most of the time, they were wrapped around workshops. I find this a really great way of travelling and enjoyed doing this when I was working for FOSSEE project and Sarai. We get to meet new people, explore the place, soak in more culture, and learn some more things while trying to help. I find this a better way of travelling than doing regular tourist package available on groupon deals.
What can I offer
From past some months I have worked on things based on thrift, nltk, OpenCV. I can help conduct basic introductory workshops based on these tools. Previously I have also worked on programming GPU using OpenCL and an Qt based GUI application for it. While at FOSSEE project we used to cover Python for Science and Engineering students at various engineering colleges, which also included LaTeX and git/hg. I use Ubuntu as my primary OS so I can even conduct a basic introductory workshop around it too.
With all this said, I am ready to travel in these regions, at my own travel expenses(I won't mind any recommendation for cheap travel alternatives too) but with little assistance from some local people who are willing to 'host' me, and who think, I can help them in their learning process.
What am I expecting
Here are things which I expect:
- A enthusiastic crowd – can't be bargained :)
- Workshop should be free and open for all.
- It would be hands-on workshop, so everyone would be expected to work and learn, first hand.
- If possible accommodation with local organisers and travel arrangements inside the country.
- I am thinking of conducting these workshops/sprints/hackathons over weekends, so availability of resources(machines for hands-on, wifi network) during that time.
- A couple of days, along with it, free, when I can roam around.
Some pointers/links
- My github account - https://github.com/baali
- My email-id - baali[at]muse-amuse[dot]in or choudhary[dot]shantanu[at]gmail[dot]com
Do get back to me, and if you think we can do something together. Email me so that we can fix dates and other details and I can arrange for my tickets at the earliest. And if we need more helping hands with workshops I am sure I can rope in my friends too.
Thank you.
Shantanu