Collecting user feedback
I love simple basic things that come together to deliver a feature.
I am working on a new product around guided meditation. I am learning what makes a good meditation session and applying it to create lot of sessions on the fly (shoutout to ffmpeg, it rocks). While the hardware is coming together at its own pace and has its own challenges (maybe I will write a separate post around it), I wanted a quick way to share these sessions with the right people and collect their comments and feedback.
My requirements were clear: clean UX that allows users to tell us their name and what they thought of the session. For users, I didn't want them to create account, authenticate etc. For backend, I didn't want to over-engineer it. A central place where I can see all the comments, a notification when I get a new feedback.
Enter: Google Forms. Here are the steps I did:
- created a google form with the questions
- published it and got the public URL
- I used a tool to get "
entries" that represented my questions in the form - build a modal, custom UI that was consistent with my app (<iframe>
embedding was not needed):
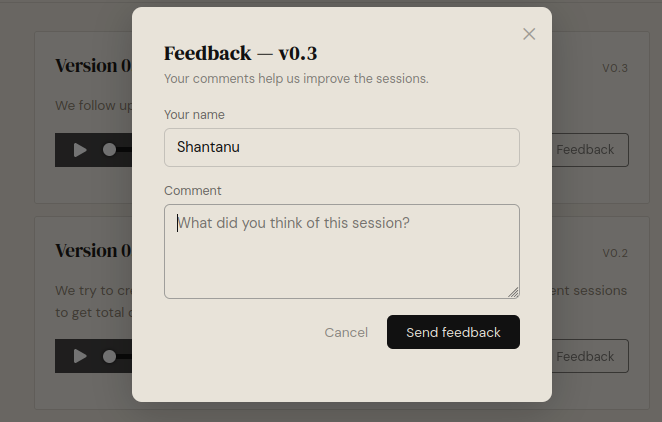
-
A POST (on backend using python
requestsor from javascript using afetchcall) request with all entries (questions) and their values. That's it. Response is registered, a new line is added to the linked spreadsheetconst GOOGLE_FORM_URL = 'https://docs.google.com/forms/d/<formID>/formResponse'; const ENTRY = { name: 'entry.1122112211', comment: 'entry.7766177172', segments: 'entry.1121121218', version: 'entry.178019201', }; const formData = new FormData(); formData.append(ENTRY.name, name); formData.append(ENTRY.comment, comment); formData.append(ENTRY.segments, segments); formData.append(ENTRY.version, modal.dataset.version); try { await fetch(GOOGLE_FORM_URL, { method: 'POST', mode: 'no-cors', // Google Forms doesn't allow CORS; submission still works body: formData, }); - I enabled email notification for new responses

When I first read about it from Claude and Stackoverflow I didn't
believe it. In the past whenever I have tried to use google products,
it was a pain, setting up authentication, configuration, permissions
etc, it was always a PAIN. I thought Google would never allow a simple
POST to register a response. But they do. Whenever a user leaves a
comment, I get an email alert, I get neat breakdown of all the
feedback on google forms response section
It is such a joy to stumble across this solution that just works. Plus, I was casually talking about it with Punch, it was TIL for him too, he loved it too and that also made me happy 😊.
Elevating the recipe
This is a follow-up on an earlier post: The right recipe. There I used Github actions to push data to a google spreadsheet that would update a looker studio dashboard.
The data we were handling didn't scale with google spreadsheet: both ingesting and accessing got slower. And we needed feature around data access controls, onboarding new clients. So we migrated to Supabase (a Postgres-based platform) and this is the new pipeline:
- Hourly API pulls, store JSON response in a postgres table
- Flatten part of JSON, subset of key value pairs into another table (materialized view)
- A dashboard connected to this view
Infrastructure on Supabase is managed using SQLAlchemy models, I use Alembic for migrations, and Github actions for automation. Everything is version controlled with separate development and production environments.
New pipeline, new challenges. As the data grew, refreshing the materialized view started taking longer and longer. Github action failed as the query to flatten the data took longer and exceeded Supabase's timeouts. This is the query that I was running:
SELECT
json_dump -> 'total' -> 'time' as time,
json_dump -> 'total' -> 'value' as energey
FROM telemetry_table
WHERE telemetry_table.json_dump -> 'total' is not null;
We would adjust timeouts on Supabase roles and in a week or two the run would fail again. With close to 35k entries, it took almost 20 seconds to refresh the view.
At some point adjusting timeout didn't cut and I started looking into
the query (explain analyze). Just parsing the JSON column was
biggest factor. And as I extracted any field it would also increase
the execution time.
Here is result from not including JSON column in query:
QUERY PLAN
Seq Scan on telemetry_table (cost=0.00..6843.29 rows=31629 width=8) (actual time=0.014..13.774 rows=31424 loops=1)
Planning Time: 0.230 ms
Execution Time: 15.178 ms
Here is result from using the JSON column, filtering null rows and
extracting fields:
QUERY PLAN
Seq Scan on telemetry_table (cost=0.00..8181.60 rows=31471 width=8) (actual time=0.524..11074.447 rows=26012 loops=1)
Filter: ((json_dump -> 'total'::text) IS NOT NULL)
Rows Removed by Filter: 5412
Planning Time: 0.249 ms
Execution Time: 11079.209 ms
Regular search and llm both suggested me to use JSONB instead of
JSON and GIN indexes. I created a backup table and altered the
column to JSONB and that reduced the refresh time to less than 2
seconds. 10x improvement:
QUERY PLAN
Seq Scan on experimental_telemetry_table (cost=0.00..10696.63 rows=43026 width=8) (actual time=0.753..405.313 rows=37030 loops=1)
Filter: ((json_dump -> 'total'::text) IS NOT NULL)
Rows Removed by Filter: 6212
Planning Time: 0.778 ms
Execution Time: 931.380 ms
This was good enough for us and I didn't need GIN index. I am not
filtering rows based on specific fields from the json data.
I will work on it more as we onboard new clients. We know the
limitation of existing system: despite the best efforts we still have
some manual steps for onboarding a new client. We have functions tied
to the project. The data is time-series and there are other well
suited databases specially meant for it. API response json varies
for each client. Lets see how the project and solution (recipe)
evolves.
Readable code
Background
I am revisiting Clojure by cleaning up and handling bad-data. Data is in a CSV file. There are two aspects to the problem - return clean rows and log/find bad ones.
This reminded me of a Clojure project I worked on in 2020 that handled drop shipping of orders from a third-party website. We would receive orders in CSV files, create these orders on our store, and respond with order tracking details in CSV format. Our store API worked with JSON data, so I had to handle the data transformation from CSV to JSON and back.
Problem: Handle the transition of data from flat to nested form
I was learning Clojure while working on that project, and I wrote the following function to flatten nested order data:
(defn single-row-per-sku
"Convert consolidated processed orders to rows containing each SKU"
[orders]
(reduce (fn [result order] (concat result (map #(merge % (dissoc order :items)) (:items order)))) [] orders))
It works—I wrote unit tests to make sure it did. But it is dense and unreadable. I can't even recall how I explained this section during code review.
I used Clojure for the Brave and True for learning the language. It was a fun and refreshing read on introducing core concepts. The function that I wrote doesn't do justice to the quality of the content.
Brave Clojure also has this relevant quote from Alan Perlis:
It is better to have 100 functions operate on one data structure than 10 functions on 10 data structures.
I came from Python background. I also didn't know about threading macros in Clojure when I wrote above function. The quote really made sense to me once I learned about threading.
As I am revising Clojure concepts I am writing a lot of small function and testing them using the REPL. In the same vein I feel following is more readable equivalent:
(defn get-address [order]
(dissoc order :items))
(defn get-items [order]
(order :items))
(defn flatten-items [order]
(let [address (get-address order)
items (get-items order)]
(->> items
(map #(merge address %)))))
(defn single-row-per-sku [orders]
(->> orders
(map flatten-items)
flatten))
Small functions. Threading macros. Names that make sense. Easy to read and functional. I don't think it's the final version-the ballad continues as I keep learning.
Getting started with powerful abstract tools: Emacs, Vim
Foundation: Text Editors
In his book The Dip, Seth Godin talks about snowboarding:
Snowboarding is a hip sport. It’s fast, exciting and reasonably priced; and it makes you look very cool. So why are there so few snowboarders? Because learning the basic skills constitutes a painful Dip. It takes a few days to get the hang of it, and, during those few days, you’ll get pretty banged up. It’s easier to quit than it is to keep going.
The brave thing to do is to tough it out and end up on the other side–getting all the benefits that come from scarcity. The mature thing to do is not even to bother starting to snowboard because you’re probably not going to make it through the Dip. And the stupid thing to do is to start, give it your best shot, waste a lot of time and money, and quit right in the middle of the Dip.
In the programming world, editors are an important basic skill-they
are like the snowboard in this analogy. I would often read about vim
and emacs. In college, I tried them a couple of times and got
stuck. vim's swap file prompt was scary. When git opened vim's
side-by-side buffer to resolve merge conflicts, I would start
sweating.
Finding the Spark
Both VIM and Emacs are powerful and ubiquitous text editors and
both are infamous for their steep learning curves. On my own, picking
up such a tool was intimidating and frustrating. Here is what did the
trick for me: watch a power user use them. It really hits you when
this happens in person. I saw someone using org-mode in emacs, its
table editor, exporting it in Markdown, HTML, and PDF, and then he
used it to create a presentation using org-reveal, I was blown away
🤯. Later another friend of mine was using emacs and tramp to make
code adjustments on a live server (avoid doing that) 🫡. During
another pairing session, my colleague was using vim, navigating
code, renaming variables with visual mode, and running macros-it was
magic 🤹🏽. These moments made these editors cool for me-simple yet
very pliable and that gave me enough escape velocity to push through
the steep learning curve.
The Learning Curve
These editors are abstract tools that carry certain labels: "hard", "for smart people only", "set in their own ways". I struggled with two things when trying to pick them up. When I was working on a problem, I didn't want to get distracted by my editor, its mode, buffers, opening and closing etc. Second, I didn't consider myself smart and I kept my distance (thinking I was being mature) from tools that carried that impression.
But once I realized editors were a fundamental skill, I realized I should invest the time, don't make it (the editor) the last thing. I kept retrying, just like how I would approach a boss fight in a game. I didn't scare that easy in the next round, I noticed patterns, found my corner, got comfortable and started attacking. It grew on me. I acquired the taste. The same approach works for all crafts. Later, as I worked on new problem, these editors didn't get in the way-they provided the structure that will helped me focus.
I was lucky to work with such power users, and they allowed me the
space to ask stupid questions. I still nag them about their setup when
we meet in person. I use Emacs. I can't program without org-mode,
magit, tramp et al. I am slowly working my way through its LSP support
and configuring and tweaking things, one language at a time. I've
tried other editors, I kept looking for these features and so far my
attempts to install plugins/addons haven't worked. I keep returning to
Emacs. As the landscape evolves with AI agents and MCP, I will
explore whether I can integrate them with Emacs or if I'll need to
adopt a more contemporary editor.
One Firmware for all ESP32 Variants: Solving Pin Mapping Pain
For my embedded project, I needed NFC card functionality for WiFi onboarding and user interactions. When integrating NFC functionality into ESP32 projects, pin mapping became a major pain point as I was working with different ESP32 boards.
Adafruit's arduino library example sets up the NFC reader in following manner:
#include <Wire.h>
// Using the SPI breakout, define the pins for SPI communication.
#define PN532_SCK (2)
#define PN532_MOSI (3)
#define PN532_SS (4)
#define PN532_MISO (5)
Adafruit_PN532 nfc(PN532_SCK, PN532_MISO, PN532_MOSI, PN532_SS);
These pins are placeholders and they would vary for each ESP32 variant and I had several: ESP-WROOM-32, ESP32-C3 Super Mini, S3, XIAO ESP32S3
I tested the reader across all these variants, different modes: SPI,
I2C, wiring and reading different NFC cards.
First challenge was to figure out the mapping of pins. I found that
espressif's arduino support is the best resource for it. For each
board the file pins_arduino.h gives us the right pins. For the
ESP32-C3 Super Mini board, the above example NFC reader code would
become:
#include <Wire.h>
#define PN532_SCK (4)
#define PN532_MOSI (6)
#define PN532_SS (7)
#define PN532_MISO (5)
Adafruit_PN532 nfc(PN532_SCK, PN532_MISO, PN532_MOSI, PN532_SS);
But as I iterated through these ESP32 variants it became quite a pain adjusting those pins in the firmware and flashing it. Eventually I realized what would simplify this: I could have a single firmware that will work with everything:
#include <Wire.h>
Adafruit_PN532 nfc(SCK, MISO, MOSI, SS);
These pins, SCK, MISO are just like another constant:
LED_BUILTIN, each Arduino board that doesn't use default pin 13,
defines it in their pins_arduino.h header. Similarly all the
variants have their own respective pins_arduino.h file with right
pins. As I select the board inside Arduino IDE, these variables are
always available. Further this pattern isn't limited to NFC readers,
all the SPI peripheral using those pins would work.
CPR for a Docker container
Background
Picture this: You're experimenting with a Docker container, enable a
feature, and suddenly your container is stuck in an endless restart
loop. In a panic, you run docker compose down and watch everything
disappear.
What You Should Do Instead
Don't lose the container, no matter how broken it is. Create a new
image from the container using docker commit: docker commit
<container-id> broken-image (you get container id using docker ps
-a command)
From here there are a couple of things you could do. I was using
Dockerfile to build and setup things. Modify it to use broken image
as base and install the missing dependencies:
FROM broken-image:latest
RUN pip install <package-name>
And with this in place I can restart the docker compose stack.
Complicated changes
In case damage to your container is more severe there will be additional steps to revive the container.
- Create image from your broken container:
docker commit <container-id> broken-image - Create a new container from this broken image with a different
entrypointcommand (default command would restart the broken stack):docker run -it --entrypoint=/bin/bash broken-image:latest - Adjust or remove your changes, install missing dependencies, run migrations, what have you
- Create a new image from this container that has all the fixes:
docker commit <container-id-with-bash-running> fixed-image -
Start a new container using this
fixed-imageand default command that brings up your original stack. In my case I removedbuildstep from mydocker-compose.ymlfile and pointed it to the new image:app: image: fixed-image:latest - Be careful with running faulty containers. I was really confused
balancing
docker composecommands and directdockercommands. I noticed thatdocker compose(re)start command would also (re)start all broken/existing containers and I had to manually remove them to be able to get the complete stack running again.
With this approach I was no longer building a new Docker
image. Instead I used docker compose to start container using
fixed-image and default command.
Summary:
- Always test changes in development first
- Use
docker commitwith your container before making risky changes
The right recipe
A colleague reached out to me for a pairing session on his project. I explained upfront that my hourly rate far exceeds most LLM subscription costs. He understood — while LLMs have their place, he needed help clarifying requirements and making real progress.
His existing setup: several machines pushing data to cloud, a looker studio dashboard connected to a placeholder google spreadsheet. To start, he wanted to make this dashboard live.
His requirements:
- A live dashboard
- Python based: his comfort zone
- Daily data pulls: sufficient for non-temporal data
The solution was obvious, I have used it before: A GitHub action that runs daily, pulls cloud data and updates his spreadsheet — instantly making his dashboard live. I understand that I am contributing to the Github actions phenomena:

The trickiest parts? Wrestling with Google's Sheets API authentication and configuring GitHub secrets properly. But once those pieces clicked, everything flowed. Four one hour focused pairing sessions, that's it. He got a working solution plus he understood all the moving parts to continue experimenting on his own.
Four hours, serverless, an elegant solution. This is what going back to first principles looks like.
Setting Up Zephyr for ESP32: A Blinky LED Journey
I recently started working with a client on an ESP32 based project. Having prior experience with Zephyr on Nordic boards, I decided to leverage Zephyr's Espressif support for this project. While the documentation mentions the classic "blinky" example, I noticed it lacked the necessary device overlay file for my specific board.
Finding the Right Example
Fortunately, I discovered that the "PWM Blinky" example included sample overlay files I could reference. After compiling the example, I encountered this error when attempting to flash the device:
([Errno 5] could not open port /dev/ttyUSB0: [Errno 5] Input/output error: '/dev/ttyUSB0')
Running stat /dev/ttyUSB0 revealed that the device belonged to the
dialout group. I fixed the permission issue by adding my user to
this group:
sudo usermod -a -G dialout $USER
After rebooting to apply the new permissions, west flash worked perfectly.
Creating the missing overlay file
The basic Blinky documentation explains the need for an overlay file
that points to the correct GPIO pin. Based on the PWM Blinky example,
I discovered my board (esp32_devkitc_wroom) has an onboard blue LED
connected to pwm_led_gpio0_2. I created following overlay file:
/ {
aliases {
led0 = &myled0;
};
leds {
compatible = "gpio-leds";
myled0: led_0 {
gpios = <&gpio0 2 GPIO_ACTIVE_LOW>;
};
};
};
Success
With the overlay in place(samples/basic/blinky/boards/esp32_devkitc_wroom_procpu.overlay),
I compiled the project and it worked:
west build -p always -b esp32_devkitc_wroom/esp32/procpu samples/basic/blinky
After flashing the board, there it was, blinking blue LED - a small victory that is still the first step and I keep revisiting it.
Next up: implementing the project's actual functionality, including WiFi provisioning, ePaper display integration, and LED ring controls.
Resolution / सलटारा
Continuing from the last post. The fact that Python interpreter didn't
catch the regex pattern in tests but threw compile error on staging
environment was very unsettling. Personally I knew that I am missing
something on my part and I was very reluctant on blaming the language
itself. Turns out, I was correct 🙈.
I was looking for early feedback and comments on the post and Punch was totally miffed by this inconsistency and specially the conclusion I was coming to
Umm, I'm not sure I'm happy with the suggestion that I should check every regex I write, with an external website tool to make sure the regex itself is a valid one. "Python interpreter ka kaam main karoon abhi?" :frown:
He quickly compared the behavior between JS(compiler complianed) and
Python(did nothing). Now that I had full attention from him there was
no more revisiting this at some later stage. We started digging. He
confirmed that the regex failed with Python2 but not with
Python3.11 with a simple command
docker run -it python:3.11 python -c 'import re; p = r"\s*+"; re.compile(p); print("yo")'
I followed up on this and that was the mistake on my part. My local
python setup was 3.11, I was using this to run my tests and staging
environment was using 3.10. When I ran my tests within containerized
setup, similar to what we used on staging, Python interpreter rightly
caught faulty regex:
re.error: multiple repeat at position 11
Something changed between python 3.11 and 3.10 release. I looked
at the release logs and noticed this new feature atomic grouping and
possessive quantifier. I am not sure how to use it or what it does
1. But with this feature, python 3.11 regex pattern: r"\s*+" is a
valid one. I was using this to run tests locally. On staging we had
python 3.10, and with it interpreter threw an error.
Lesson learned:
I was testing things by running things locally. Don't do that. Setup a stack and get is as close to the staging and production as possible. And always, always run tests within it.
You pull an end of a mingled yarn,
to sort it out,
looking for a resolution but there is none,
it is just layers and layers.
Assumptions / घारणा
In the team I started working with recently, I am advocating for code reviews, best practices, tests and using CI/CD. I feel in Python ecosystem it is hard to push reliable code without these practices.
I was assigned an issue to find features from text and had to extract money figures. I started searching for existing libraries (humanize, spacy, numerize, advertools, price-parser). These libraries always hit an edge case with my requirements. I drafted an OpenAI prompt and got a decent regex pattern that covered most of my requirements. I made a few improvements to the pattern and wrote unit and integration tests to confirm that the logic was covering everything I wanted. So far so good. I got the PR approved, merged and deployed. Only to find that the code didn't work and it was breaking on staging environment.
As the prevailing wisdom goes around regular expressions based on 1997 chestnut
Some people, when confronted with a problem, think "I know, I'll use regular expressions." Now they have two problems.
I have avoided regular expressions, and here I am.
I was getting following stacktrace:
File "/lib/number_parser.py", line 19, in extract_numbers
pattern = re.compile("|".join(monetary_patterns))
File "/usr/local/lib/python3.10/re.py", line 251, in compile
return _compile(pattern, flags)
File "/usr/local/lib/python3.10/re.py", line 303, in _compile
p = sre_compile.compile(pattern, flags)
File "/usr/local/lib/python3.10/sre_compile.py", line 788, in compile
p = sre_parse.parse(p, flags)
File "/usr/local/lib/python3.10/sre_parse.py", line 955, in parse
p = _parse_sub(source, state, flags & SRE_FLAG_VERBOSE, 0)
File "/usr/local/lib/python3.10/sre_parse.py", line 444, in _parse_sub
itemsappend(_parse(source, state, verbose, nested + 1,
File "/usr/local/lib/python3.10/sre_parse.py", line 672, in _parse
raise source.error("multiple repeat",
re.error: multiple repeat at position 11
Very confusing. Seems there was an issue with my regex pattern. But
the logic worked, I tested it. The pattern would fail for a certain
type of input and work for others. What gives? I shared the regex
pattern with a colleague and he promptly identified the issue, there
was a redundant + in my pattern. I wanted to look for empty spaces
and I had used a wrong pattern r'\s*+'.
I understand that Python is a interpreted and dynamically typed and that's why I wrote those tests(unit AND integration), containerized the application to avoid the wat. And here I was, despite all the measures, preaching best practices and still facing such a bug for the first time. I assumed that interpreter will do its job and complain about the buggy regex pattern and my tests would fail. Thanks to Punch we further dug into this behavior here.
A friend of mine, Tejaa had shared a regex resource:
https://regex-vis.com/, it is a visual representation (state diagram
of sorts) of the grammar. I tested my faulty regex pattern with \s*+
and the site reported: Error: nothing to repeat. This is better,
error is similar with what I was noticing in my stack trace. I also
tested the fixed pattern and the site showed a correct representation
of what I wanted.
Always confirm your assumptions.
assumption is the mother of all mistakes (fuckups)